AI生成工具
两年前我有了个掌阅阅读器,于是我开始在阅读器上看书,从此一发不可收,导致我两年没看一本纸质书。不过,你别说,电子书还真是省钱。zlib上下载,导入到kindle或者微信读书里去看,这两年看的书愣是一分钱没花…
如果问我看电子书有什么好处,我觉得是方便做笔记。其实,以前我是一个看书从不做笔记的人,那是因为年轻时记忆力好盲目自信,现在衰退得厉害,看完啥都记不住,不做笔记跟没看一样,后来开始记笔记,但是一直没有好方法。虽然看纸质书的时候,看到好玩的也会拿手机拍发到豆瓣读书笔记里看完了再整理成博客,但是实在是不方便,一张张照片,也很难整理。看电子书就方便多了,看的时候随便拿手指划划,看完直接能导出。
kindle的读书笔记导出的是html格式,通过脚本可以很方便地转成markdown。我之前还发过转换的脚本–>kindle笔记转成markdown
微信读书没有导出笔记的功能,只能在网页版上全部复制出来,而且格式比较奇葩,太多特殊字符,发表的想法与原文也别扭。直接贴到博客里格式就有点难于接受。所以很长时间以来,我都是在kindle里看书。
但是与微信读书的查询功能相比,kindle的字典和搜索功能实在是垃圾,而且因为不可知的原因我的阅读器上的kindle下载不了字典。尤其现在微信读书有了AI的加持。kindle的下场就是被我弃如敝帚。
微信读书啥都好,就是导出笔记不行,那么我们就来解决笔记的问题。以前得费劲写脚本,现在不用了,现在有AI了,让AI来转格式,直接把复制出的笔记让他给转成markdown。但是这种方法不稳定,来回调整格式也让人火大,还是让它生成脚本。我试了一下,几轮对话调整之后,基本可用,最终脚本如下:
#!/usr/bin/env python3
"""
微信读书笔记 → Markdown 转换脚本
用法:python convert_notes.py <输入文件> <输出文件>
"""
import sys
def convert_weixin_notes(input_path, output_path):
with open(input_path, 'r', encoding='utf-8') as f:
text = f.read()
lines = text.strip().split('\n')
result = []
i = 0
n = len(lines)
# 用于暂存想法内容(想法标题 + 想法正文)
idea_buffer = []
collecting_idea = False
while i < n:
line = lines[i].rstrip()
# ---- 第1行:书籍标题 ----
if i == 0 and line.startswith('《') and '》' in line:
result.append(f'# {line}')
i += 1
continue
# ---- 第2行:作者(可选) ----
if i == 1 and line and not line.startswith('◆') and '个笔记' not in line:
result.append(line)
i += 1
continue
# ---- 第3行:笔记数 ----
if i == 2 and '个笔记' in line:
result.append(line)
i += 1
continue
# ---- 空行 ----
if not line:
if collecting_idea:
idea_buffer.append('') # 想法中的空行保留
else:
result.append('')
i += 1
continue
# ---- 章节标题(如"推荐序"、"第1章"等) ----
# 不在收集想法时才判断章节标题
if not collecting_idea and not line.startswith('◆') and not line.startswith('原文:') and len(line) < 60:
# 判断是否为章节标题:不包含特殊符号,且不是笔记数统计
if '个笔记' not in line and '来自微信读书' not in line and '发表想法' not in line:
result.append(f'## {line}')
i += 1
continue
# ---- 处理 ◆ 开头的行 ----
if line.startswith('◆'):
content = line[1:].strip()
# 判断是否为"发表想法"标记
if '发表想法' in content:
# 开始收集想法,但不保存"发表想法"行
collecting_idea = True
idea_buffer = [] # 不保存"发表想法"标记行
i += 1
continue
else:
# 这是普通原文
if collecting_idea or idea_buffer:
# 先检查想法缓冲区中是否有"原文:"开头的行
original_text = None
idea_lines = []
for idea_line in idea_buffer:
if idea_line.startswith('原文:'):
original_text = idea_line[3:] # 去掉"原文:"前缀
else:
idea_lines.append(idea_line)
# 输出原文引用(优先使用想法缓冲区中的"原文:"内容)
if original_text:
result.append(f'> {original_text}')
else:
# 去掉可能存在的"原文:"前缀
if content.startswith('原文:'):
result.append(f'> {content[3:]}')
else:
result.append(f'> {content}')
# 再输出收集到的想法内容(普通文本)
for idea_line in idea_lines:
result.append(idea_line)
# 清空想法缓冲区
idea_buffer = []
collecting_idea = False
else:
# 无待输出的想法,直接输出原文引用(去掉"原文:"前缀)
if content.startswith('原文:'):
result.append(f'> {content[3:]}')
else:
result.append(f'> {content}')
i += 1
continue
# ---- 其他行(想法正文等) ----
if collecting_idea:
idea_buffer.append(line)
i += 1
continue
# ---- 默认:直接输出(如"-- 来自微信读书") ----
result.append(line)
i += 1
# 文件末尾可能残留未输出的想法(极少见),这里忽略
with open(output_path, 'w', encoding='utf-8') as f:
f.write('\n'.join(result))
print(f'转换完成!输出文件:{output_path}')
if __name__ == '__main__':
if len(sys.argv) != 3:
print('用法:python convert_notes.py <输入文件.txt> <输出文件.md>')
sys.exit(1)
input_file = sys.argv[1]
output_file = sys.argv[2]
convert_weixin_notes(input_file, output_file)
后来我又想,现在腾讯有免费的egdeone,把它转成网页放到公网岂不美哉。
 腾讯好啊,edgeone 得用。
腾讯好啊,edgeone 得用。
于是让AI把python转成web vite工程,整了个二级域名一发布,这小工具不就成了。
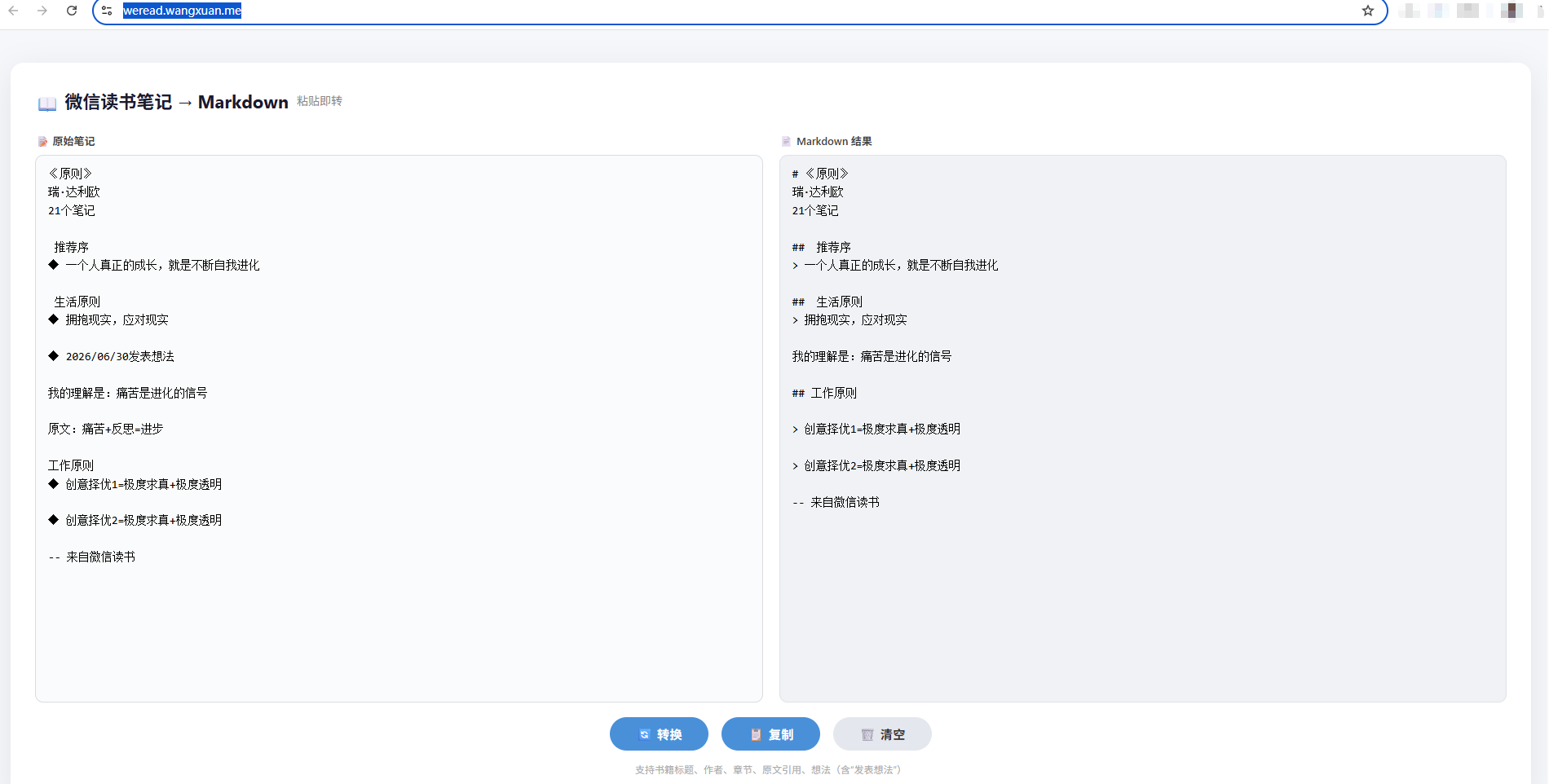 https://weread.wangxuan.me/
这是地址,有兴趣的可以试试。
https://weread.wangxuan.me/
这是地址,有兴趣的可以试试。
源码也有: https://gitee.com/wangyidao/weread
具体发布过程可以参考这个:用Gitee和EdgeOne Pages搭建支持外链的免费相册


