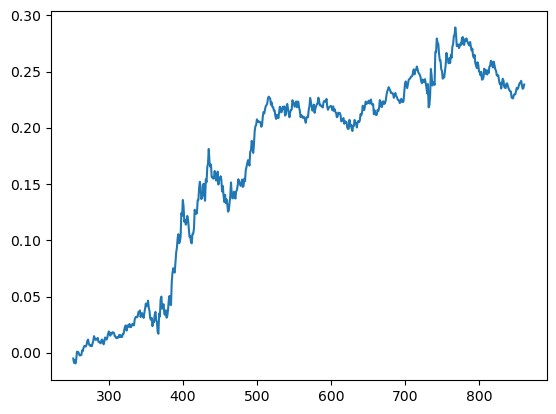
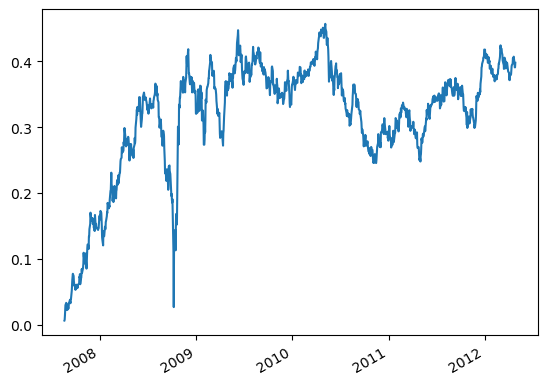
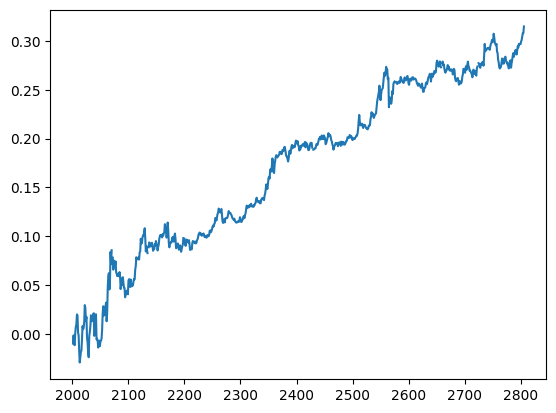
# Example 5.1: Pair Trading USD.AUD vs USD.CAD Using the Johansen Eigenvectorimport numpy as npimport pandas as pd#import matplotlib.pyplot as plt#import statsmodels.formula.api as sm#import statsmodels.tsa.stattools as tsimport statsmodels.tsa.vector_ar.vecm as vmdf1=pd.read_csv('datas/inputData_USDCAD_20120426.csv')df1['Date']=pd.to_datetime(df1['Date'], format='%Y%m%d').dt.date # remove HH:MM:SSdf1.rename(columns={'Close': 'CAD'}, inplace=True)df1['CAD']=1/df1['CAD']df2=pd.read_csv('datas/inputData_AUDUSD_20120426.csv')df2['Date']=pd.to_datetime(df2['Date'], format='%Y%m%d').dt.date # remove HH:MM:SSdf2.rename(columns={'Close': 'AUD'}, inplace=True)df=pd.merge(df1, df2, how='inner', on='Date')df.set_index('Date', inplace=True)trainlen=250lookback=20hedgeRatio=np.full(df.shape, np.NaN)numUnits=np.full(df.shape[0], np.NaN)for t inrange(trainlen+1, df.shape[0]):# Johansen test result=vm.coint_johansen(df.values[(t-trainlen-1):t-1], det_order=0, k_ar_diff=1) hedgeRatio[t,:]=result.evec[:, 0] yport=pd.DataFrame(np.dot(df.values[(t-lookback):t], result.evec[:, 0])) # (net) market value of portfolio ma=yport.mean() mstd=yport.std() numUnits[t]=-(yport.iloc[-1,:]-ma)/mstd positions=pd.DataFrame(np.expand_dims(numUnits, axis=1)*hedgeRatio)*df.values # results.evec(:, 1)' can be viewed as the capital allocation, while positions is the dollar capital in each ETF.pnl=np.sum((positions.shift().values)*(df.pct_change().values), axis=1)# daily P&L of the strategyret=pnl/np.sum(np.abs(positions.shift()), axis=1)(np.cumprod(1+ret)-1).plot()print('APR=%f Sharpe=%f'% (np.prod(1+ret)**(252/len(ret))-1, np.sqrt(252)*np.mean(ret)/np.std(ret)))# APR=0.064512 Sharpe=1.362926
C:\Users\win10\AppData\Local\Temp\ipykernel_20380\4249882280.py:37: FutureWarning: Calling float on a single element Series is deprecated and will raise a TypeError in the future. Use float(ser.iloc[0]) instead
numUnits[t]=-(float(yport.iloc[-1,:])-ma)/mstd
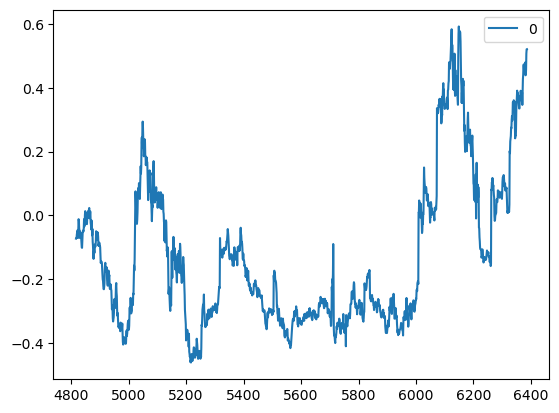
# Example 5.3: Estimating Spot and Roll Returns Using the Constant Returns Modelimport numpy as npimport pandas as pd#import matplotlib.pyplot as pltimport statsmodels.api as sm#import statsmodels.tsa.stattools as ts#import statsmodels.tsa.vector_ar.vecm as vmdf=pd.read_csv('datas/inputDataDaily_C2_20120813.csv')df['Date']=pd.to_datetime(df['Date'], format='%Y%m%d').dt.date # remove HH:MM:SSdf.set_index('Date', inplace=True)# Find spot pricesspot=df['C_Spot']df.drop('C_Spot', axis=1, inplace=True)T=sm.add_constant(range(spot.shape[0]))model=sm.OLS(np.log(spot), T)res=model.fit() # Note this can deal with NaN in top rowprint('Average annualized spot return=', 252*res.params.iloc[1])#Average annualized spot return= 0.02805562210100287# Fitting gamma to forward curvegamma=np.full(df.shape[0], np.nan)for t inrange(df.shape[0]): idx=np.where(np.isfinite(df.iloc[t, :]))[0] idxDiff = np.roll(idx, -1) - idx all_ones =all(idxDiff[0:4]==1) if (len(idx)>=5) and all_ones: FT=df.iloc[t, idx[:5]] T=sm.add_constant(range(FT.shape[0])) model=sm.OLS(np.log(FT.values), T) res=model.fit() gamma[t]=-12*res.params[1]pd.DataFrame(gamma).plot()print('Average annualized roll return=', np.nanmean(gamma))# Average annualized roll return= -0.12775650227459556
Average annualized spot return= 0.02805562210100191
Average annualized roll return= -0.1277565022746007