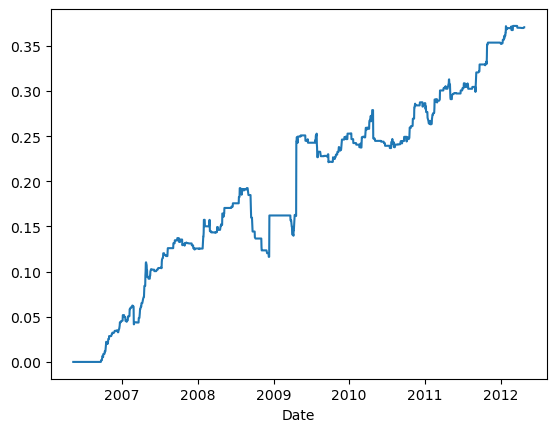
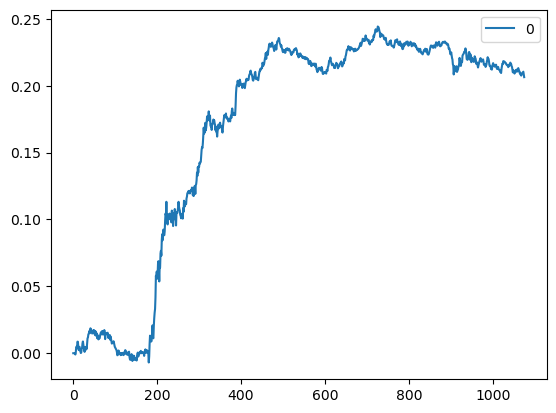
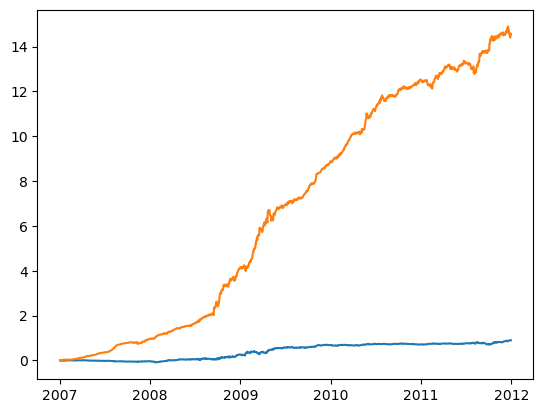
# Example 4.2: Arbitrage between SPY and Its Component Stocksimport numpy as npimport pandas as pd#import matplotlib.pyplot as plt#import statsmodels.formula.api as sm#import statsmodels.tsa.stattools as tsimport statsmodels.tsa.vector_ar.vecm as vm# Stockscl=pd.read_csv('datas/inputDataOHLCDaily_20120424_cl.csv')stocks=pd.read_csv('datas/inputDataOHLCDaily_20120424_stocks.csv')cl['Var1']=pd.to_datetime(cl['Var1'], format='%Y%m%d').dt.date # remove HH:MM:SScl.columns=np.insert(stocks.values, 0, 'Date')cl.set_index('Date', inplace=True)# ETFscl_etf=pd.read_csv('datas/inputData_ETF_cl.csv')etfs=pd.read_csv('datas/inputData_ETF_stocks.csv')cl_etf['Var1']=pd.to_datetime(cl_etf['Var1'], format='%Y%m%d').dt.date # remove HH:MM:SScl_etf.columns=np.insert(etfs.values, 0, 'Date')cl_etf.set_index('Date', inplace=True)# Merge on common datesdf=pd.merge(cl, cl_etf, how='inner', on='Date')cl_stocks=df[cl.columns]cl_etf=df[cl_etf.columns]# Use SPY onlycl_etf=cl_etf['SPY'] # This turns cl_etf into SeriestrainDataIdx=df.index[(df.index > pd.to_datetime("2007-01-01").date()) & (df.index <= pd.to_datetime("2007-12-31").date())]testDataIdx =df.index[df.index > pd.to_datetime("2007-12-31").date()]# 我们基于约翰森检验的原理对SPY基金的每只成分股与SPY基金本身之间的协整关系进行测试,之后我们发现:有98只股票分别与SPY基金具有协整关系。# 现在,我们可以将所有与SPY基金具有协整关系的股票之多头形式构成一个投资组合,且配置同样的资本,但是,我们还必须测试这个投资组合与SPY基金的协整关系,isCoint=np.full(stocks.shape[1], False)for s inrange(stocks.shape[1]):# Combine the two time series into a matrix y2 for input into Johansen test y2=pd.concat([cl_stocks.loc[trainDataIdx].iloc[:, s], cl_etf.loc[trainDataIdx]], axis=1) y2=y2.loc[y2.notnull().all(axis=1),]if (y2.shape[0] >250):# Johansen test 对每个成分股与SPY进行协整检验 result=vm.coint_johansen(y2.values, det_order=0, k_ar_diff=1)if (result.lr1[0] > result.cvt[0,0]): # 如果存在协整关系,则将对应的成分股标记为True isCoint[s]=Trueprint(isCoint.sum())yN=cl_stocks.loc[trainDataIdx, isCoint]# 计算仅做多组合的净市场价值logMktVal_long=np.sum(np.log(yN), axis=1) # The net market value of the long-only portfolio is same as the "spread"# Confirm that the portfolio cointegrates with SPY 确认组合与SPY的协整关系ytest=pd.concat([logMktVal_long, np.log(cl_etf.loc[trainDataIdx])], axis=1)result=vm.coint_johansen(ytest, det_order=0, k_ar_diff=1)print(result.lr1)print(result.cvt)print(result.lr2)print(result.cvm)# 上述约翰森测试表明股票的多头组合与SPY基金的协整属性达到95%以上的概率。所以,我们可以构建一个包括股票和SPY基金在内的多单-空单相间的平稳投资组合,# 同时,我们可以使用约翰森检验中的特征向量来确定SPY基金与股票投资组合的权重(事实上,即使二者之间存在协整关系,我们也可以选择特征向量矩阵eigenmatrix中的、位于第一列的最大值来构建平稳的投资组合)。#Apply linear mean-reversion model on test set 应用线性均值回归模型yNplus=pd.concat([cl_stocks.loc[testDataIdx, isCoint], pd.DataFrame(cl_etf.loc[testDataIdx])], axis=1) # Array of stock and ETF prices# 计算测试集中的投资组合权重weights=np.column_stack((np.full((testDataIdx.shape[0], isCoint.sum()), result.evec[0,0]), np.full((testDataIdx.shape[0], 1), result.evec[1, 0]))) # Array of log market value of stocks and ETF's# 计算投资组合的净市场价值logMktVal=np.sum(weights*np.log(yNplus), axis=1) # Log market value of long-short portfoliolookback=5# 计算投资组合的单位资本投入numUnits =-(logMktVal-logMktVal.rolling(lookback).mean())/logMktVal.rolling(lookback).std() # capital invested in portfolio in dollars. movingAvg and movingStd are functions from epchan.com/book2# 计算每日持仓positions=pd.DataFrame(np.expand_dims(numUnits, axis=1)*weights)# results.evec(:, 1)' can be viewed as the capital allocation, while positions is the dollar capital in each ETF.pnl=np.sum((positions.shift().values)*(np.log(yNplus)-np.log(yNplus.shift()).values), axis=1) # daily P&L of the strategy# print(positions.shift())denominator = np.sum(np.abs(positions.shift()), axis=1) # print(denominator.values)# print(pnl.values)denominator = np.where(denominator ==0, 1e-9, denominator) # 使用一个非常小的数替换零# print(denominator)ret=pd.DataFrame(pnl.values/denominator)(np.cumprod(1+ret)-1).plot()print('APR=%f Sharpe=%f'% ((np.prod(1+ret,axis=0)**(252/len(ret))-1).iloc[0], (np.sqrt(252)*np.mean(ret)/np.std(ret,axis=0)).iloc[0]))