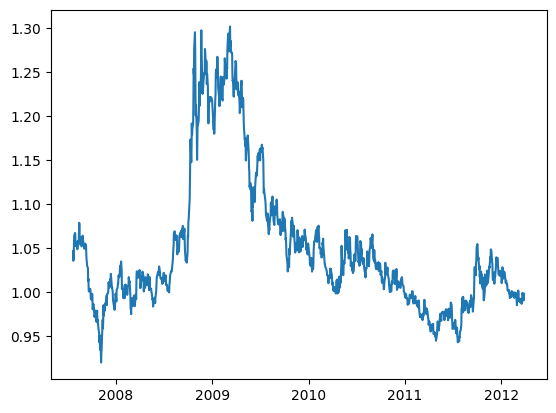
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom statsmodels.tsa.stattools import adfullerimport statsmodels.api as sm# from genhurst import genhurst def genhurst(z):# =============================================================================# calculation of Hurst exponent given log price series z# ============================================================================= z=pd.DataFrame(z)# 计算一系列时间延迟 taus,这些时间延迟是时间序列长度的十分之一左右。时间延迟不能与时间序列长度相同,因为这会导致统计不稳定。 taus=np.arange(np.round(len(z)/10)).astype(int) # We cannot use tau that is of same magnitude of time series length # 初始化一个空数组 logVar,用于存储每个时间延迟对应的对数方差。 logVar=np.empty(len(taus)) # log variance# 对于每个时间延迟 tau,计算 z 的差分序列(即相邻元素之间的差异)的方差,并取对数。将结果存储在 logVar 数组中。for tau in taus: logVar[tau]=np.log(z.diff(tau).var(ddof=0))# 创建两个数组 X 和 Y,分别表示时间延迟的对数和对应的对数方差。 X=np.log(taus) Y=logVar[:len(taus)]# 删除 logVar 中包含非有限值(如NaN或无穷大)的元素对应的 X 和 Y 中的元素。 X=X[np.isfinite(logVar)] Y=Y[np.isfinite(logVar)]# pd.DataFrame(np.asmatrix([X, Y]).T).to_csv('XY.csv') X = sm.add_constant(X)# plt.scatter(X[:,1], Y) # for debug only# 使用 statsmodels 库中的 OLS 函数拟合一个线性回归模型,其中 Y 是因变量,X 是自变量(包括一个常数项)。 model=sm.OLS(Y, X) results=model.fit()# 从拟合结果中提取 Hurst 指数 H(即斜率的一半)和相应的 p 值 pVal H=results.params[1]/2 pVal=results.pvalues[1]return H, pValdf=pd.read_csv('datas/inputData_USDCAD.csv')# print(df)df.set_index('Date',inplace=True)y=df.loc[df['Time']==1659, 'Close']# 将索引转换为matplotlib可识别的日期格式y.index = pd.to_datetime(y.index,format='%Y%m%d')# print(y)plt.plot(y)# y:要检验的时间序列。# maxlag:最大滞后阶数,用于构建ADF检验的模型。这里设置为1。# regression:回归类型。'c'表示在回归模型中包含常数项。# autolag:自动选择滞后阶数。这里设置为None,表示不自动选择滞后阶数。results=adfuller(y, maxlag=1, regression='c', autolag=None)# adfuller 函数是 statsmodels 库中的一个函数,用于执行 Augmented Dickey-Fuller (ADF) 单位根检验# Test Statistic(检验统计量):这是用于检验单位根假设的统计量。如果此值小于临界值,则拒绝原假设,认为时间序列是平稳的。# p-value(p值):这是检验统计量的概率值。如果 p 值小于预设的显著性水平(通常为 0.05),则拒绝原假设,认为时间序列是平稳的。# Critical Values(临界值):这是一组用于与检验统计量进行比较的值。通常有三个临界值,分别对应于 1%、5% 和 10% 的显著性水平。如果检验统计量小于这些临界值,则拒绝原假设。# Number of Lags Used(使用的滞后阶数):这是用于 ADF 检验的滞后阶数。滞后阶数的选择会影响检验的结果。# Number of Observations Used in Regression Analysis(回归分析中使用的观测值数量):这是用于回归分析的观测值数量。# Critical Values (1%, 5%, and 10%)(临界值,1%、5% 和 10%):这是一组用于与检验统计量进行比较的值,分别对应于 1%、5% 和 10% 的显著性水平。# ADF Statistic(ADF 统计量):这是 ADF 检验的主要统计量,与 Test Statistic 相同。# p-value (Adjusted)(调整后的 p 值):这是调整后的 p 值,考虑了滞后阶数的选择。print(results)# Find Hurst exponentH, pVal=genhurst(np.log(y))print("H=%f pValue=%f"% (H, pVal))
C:\Users\win10\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.9_qbz5n2kfra8p0\LocalCache\local-packages\Python39\site-packages\pandas\core\arraylike.py:402: RuntimeWarning: divide by zero encountered in log
result = getattr(ufunc, method)(*inputs, **kwargs)
C:\Users\win10\AppData\Local\Temp\ipykernel_22572\527508146.py:22: RuntimeWarning: divide by zero encountered in log
X=np.log(taus)
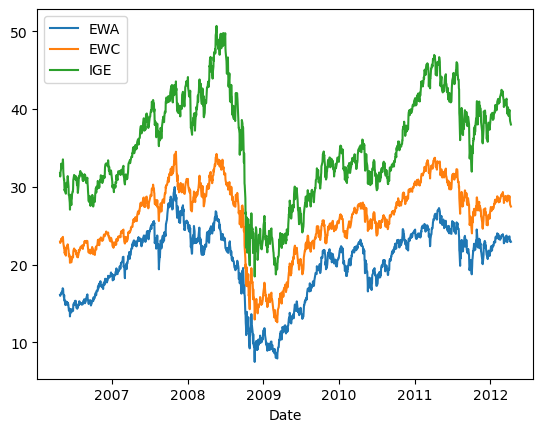
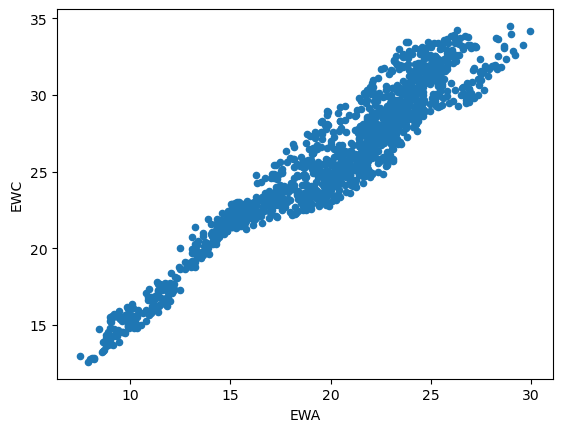
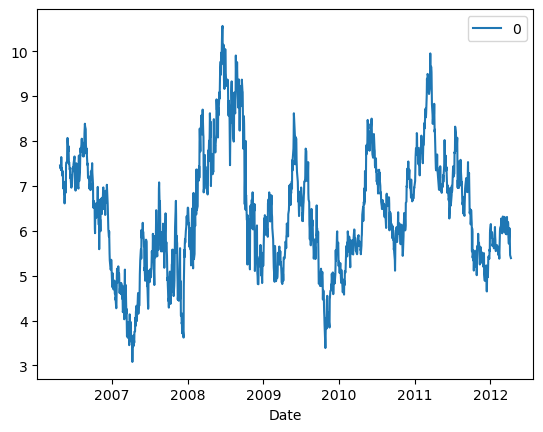
# Using the CADF test for cointegrationimport numpy as npimport pandas as pd#import matplotlib.pyplot as pltimport statsmodels.formula.api as smimport statsmodels.tsa.stattools as tsimport statsmodels.tsa.vector_ar.vecm as vmdf=pd.read_csv('datas/inputData_EWA_EWC_IGE.csv')df['Date']=pd.to_datetime(df['Date'], format='%Y%m%d').dt.date # remove HH:MM:SSdf.set_index('Date', inplace=True)# 绘制EWA和EWC的时间序列图df.plot()# 绘制EWA和EWC的散点图df.plot.scatter(x='EWA', y='EWC')# 使用普通最小二乘法(OLS)拟合EWA和EWC之间的关系results=sm.ols(formula="EWC ~ EWA", data=df[['EWA', 'EWC']]).fit()# 这行代码打印出模型的参数,包括截距和斜率print(results.params)# 计算对冲比率hedgeRatio=results.params[1]print('hedgeRatio=%f'% hedgeRatio)# 绘制残差图pd.DataFrame((df['EWC']-hedgeRatio*df['EWA'])).plot()# cadf testcoint_t, pvalue, crit_value=ts.coint(df['EWA'], df['EWC'])# coint_t:t统计量,用于检验两个序列是否协整。# pvalue:p值,用于判断t统计量的显著性。如果p值小于某个显著性水平(如0.05),则拒绝原假设(即两个序列不协整)。# crit_value:临界值,用于与t统计量进行比较。print('t-statistic=%f'% coint_t)print('pvalue=%f'% pvalue)print('crit_value:',crit_value)# Johansen testresult=vm.coint_johansen(df[['EWA', 'EWC']].values, det_order=0, k_ar_diff=1)# result.lr1:第一个特征值的迹统计量。# result.cvt:第一个特征值的临界值。# result.lr2:第二个特征值的迹统计量。# result.cvm:第二个特征值的临界值。# 约翰森检验的输出结果包括迹统计量和相应的临界值,用于判断多个时间序列之间是否存在协整关系。如果迹统计量大于临界值,则拒绝原假设(即不存在协整关系)。print(result)print('result.lr1:',result.lr1)print('result.cvt:',result.cvt)print('result.lr2:',result.lr2)print('result.cvm:',result.cvm)# Add IGE for Johansen testresult=vm.coint_johansen(df.values, det_order=0, k_ar_diff=1)print(result)print('result.lr1:',result.lr1)print('result.cvt:',result.cvt)print('result.lr2:',result.lr2)print('result.cvm:',result.cvm)# 特征值print('result.eig:',result.eig) # eigenvalues# 特征向量print('result.evec:',result.evec) # eigenvectors# 计算投资组合的市值 result.evec[:, 0] 是一个NumPy数组操作,它表示从result.evec这个二维数组中取出所有行(用 : 表示)的第0列(用 0 表示)的元素# np.dot 是 NumPy 库中的一个函数,用于计算两个数组的点积。它可以用于计算两个向量的点积,或者计算一个矩阵与另一个矩阵的乘积。# 这里的"市值"并不是传统意义上的市值,而是通过主成分分析得到的一个度量值。这个度量值可以帮助我们理解数据的主要变化趋势和结构。yport=pd.DataFrame(np.dot(df.values, result.evec[:, 0])) # (net) market value of portfolioylag=yport.shift()deltaY=yport-ylagdf2=pd.concat([ylag, deltaY], axis=1)df2.columns=['ylag', 'deltaY']regress_results=sm.ols(formula="deltaY ~ ylag", data=df2).fit() # Note this can deal with NaN in top rowprint(regress_results.params)halflife=-np.log(2)/regress_results.params['ylag']print('halflife=%f days'% halflife)# Apply a simple linear mean reversion strategy to EWA-EWC-IGE# 设置回望期为上面找到的半衰期lookback=np.round(halflife).astype(int) # setting lookback to the halflife found above# yport.rolling(lookback).mean() 计算了一个移动平均值,窗口大小为 lookback。这个移动平均值代表了在过去 lookback 个时间点的平均市值。# yport.rolling(lookback).std() 计算了一个移动标准差,窗口大小为 lookback。这个移动标准差代表了在过去 lookback 个时间点的市值波动程度。# (yport - yport.rolling(lookback).mean()) 计算了每个时间点的市值与其移动平均值的差值。正值表示市值高于平均值,负值表示市值低于平均值。# -(yport - yport.rolling(lookback).mean()) / yport.rolling(lookback).std() 计算了每个时间点的单位数量。正值表示买入,负值表示卖出。单位数量的计算公式为:(市值 - 移动平均值) / 移动标准差。这个公式实际上计算了一个标准化后的差值,使得单位数量在不同的时间点和不同的投资组合之间具有可比性。numUnits =-(yport-yport.rolling(lookback).mean())/yport.rolling(lookback).std() # capital invested in portfolio in dollars. movingAvg and movingStd are functions from epchan.com/book2print('numUnits:',numUnits)# 计算了基于线性均值回归策略的投资组合的市值分布# result.evec[:, 0] 是一个一维数组,表示第一个特征向量。这个特征向量是从主成分分析(PCA)或其他类似方法中得到的。# np.expand_dims(result.evec[:, 0], axis=1).T 将一维数组转换为二维数组,并进行转置。这样做的目的是为了使其能够与 numUnits.values 相乘。# np.dot(numUnits.values, np.expand_dims(result.evec[:, 0], axis=1).T) 计算单位数量与特征向量的点积。这个点积表示每个投资组合单位在第一个特征向量方向上的投影。# np.dot(numUnits.values, np.expand_dims(result.evec[:, 0], axis=1).T) * df.values 将点积结果与原始数据相乘,得到每个投资组合单位在每个资产上的市值。positions=pd.DataFrame(np.dot(numUnits.values, np.expand_dims(result.evec[:, 0], axis=1).T)*df.values) # results.evec(:, 1)' can be viewed as the capital allocation, while positions is the dollar capital in each ETF.print('positions:',positions)print('np.expand_dims(result.evec[:, 0], axis=1).T : ',np.expand_dims(result.evec[:, 0], axis=1).T)print('np.dot(numUnits.values, np.expand_dims(result.evec[:, 0], axis=1).T):',np.dot(numUnits.values, np.expand_dims(result.evec[:, 0], axis=1).T))# 计算了基于线性均值回归策略的投资组合的每日收益(P&L)# positions.shift().values:将 positions DataFrame 向前移动一个时间点,得到前一天的投资组合市值。# df.pct_change().values:计算原始数据(df)的每日百分比变化。# (positions.shift().values)*(df.pct_change().values):将前一天的投资组合市值与每日百分比变化相乘,得到每日收益。# np.sum((positions.shift().values)*(df.pct_change().values), axis=1):沿着列方向(axis=1)求和,得到每个时间点的总收益。pnl=np.sum((positions.shift().values)*(df.pct_change().values), axis=1) # daily P&L of the strategy# pnl:上一行代码计算出的每日收益。# np.sum(np.abs(positions.shift()), axis=1):计算前一天的投资组合市值的绝对值之和。# ret = pnl / np.sum(np.abs(positions.shift()), axis=1):将每日收益除以前一天的投资组合市值的绝对值之和,得到每日收益率。ret=pnl/np.sum(np.abs(positions.shift()), axis=1)# np.cumprod(1+ret):计算每日收益率的累积乘积,得到累计收益率。# np.cumprod(1+ret)-1:将累计收益率减去1,得到累计收益。pd.DataFrame((np.cumprod(1+ret)-1)).plot()print('============')print('np.prod(1+ret):',np.prod(1+ret))print('252/len(ret):',252/len(ret))# np.prod() 是 NumPy 库中的一个函数,用于计算数组中所有元素的乘积。这个函数可以用于计算一组数值的乘积,例如计算一组收益率的乘积以得到累积收益率。print('APR=%f Sharpe=%f'% (np.prod(1+ret)**(252/len(ret))-1, np.sqrt(252)*np.mean(ret)/np.std(ret)))# APR=0.125739 Sharpe=1.391310
Intercept 6.411331
EWA 0.962429
dtype: float64
hedgeRatio=0.962429
t-statistic=-3.063528
pvalue=0.095866
crit_value: [-3.90376106 -3.34020915 -3.04728056]
<statsmodels.tsa.vector_ar.vecm.JohansenTestResult object at 0x000001E479B796D0>
result.lr1: [19.98321869 3.98276124]
result.cvt: [[13.4294 15.4943 19.9349]
[ 2.7055 3.8415 6.6349]]
result.lr2: [16.00045745 3.98276124]
result.cvm: [[12.2971 14.2639 18.52 ]
[ 2.7055 3.8415 6.6349]]
<statsmodels.tsa.vector_ar.vecm.JohansenTestResult object at 0x000001E40D6A4490>
result.lr1: [34.42862022 17.53171895 4.47102054]
result.cvt: [[27.0669 29.7961 35.4628]
[13.4294 15.4943 19.9349]
[ 2.7055 3.8415 6.6349]]
result.lr2: [16.89690127 13.06069841 4.47102054]
result.cvm: [[18.8928 21.1314 25.865 ]
[12.2971 14.2639 18.52 ]
[ 2.7055 3.8415 6.6349]]
result.eig: [0.01121626 0.00868086 0.00298021]
result.evec: [[ 0.7599635 -0.11204898 0.0789828 ]
[-1.04602749 -0.5796762 0.26467204]
[ 0.22330592 0.53159644 -0.09515547]]
Intercept -0.115768
ylag -0.030586
dtype: float64
halflife=22.662578 days
numUnits: 0
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
1495 1.266708
1496 0.694832
1497 -0.277333
1498 -1.594578
1499 -1.588591
[1500 rows x 1 columns]
positions: 0 1 2
0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
3 NaN NaN NaN
4 NaN NaN NaN
... ... ... ...
1495 22.747467 -38.160335 11.280594
1496 12.282373 -20.619697 6.125721
1497 -4.843326 8.085019 -2.399788
1498 -28.017310 46.219527 -13.694791
1499 -27.682721 45.630541 -13.480184
[1500 rows x 3 columns]
np.expand_dims(result.evec[:, 0], axis=1).T : [[ 0.7599635 -1.04602749 0.22330592]]
np.dot(numUnits.values, np.expand_dims(result.evec[:, 0], axis=1).T): [[ nan nan nan]
[ nan nan nan]
[ nan nan nan]
...
[-0.21076268 0.29009756 -0.06193002]
[-1.21182137 1.66797282 -0.3560788 ]
[-1.20727087 1.66170944 -0.35474169]]
============
np.prod(1+ret): 2.0238397644099786
252/len(ret): 0.168
APR=0.125739 Sharpe=1.402653
C:\Users\win10\AppData\Local\Temp\ipykernel_15472\4197053767.py:22: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
hedgeRatio=results.params[1]